IA de recrutement : comment 98 % du Fortune 500 decide qui entre chez eux
98,4 %. C'est la proportion du Fortune 500 qui utilise de l'IA dans son recrutement. Presque aucune n'est obligée de dire ce que fait cette IA, ni pourquoi elle t'a refusé.
98,4 %. C'est la proportion du Fortune 500 qui utilise de l'IA dans son recrutement. Presque aucune n'est obligée de dire ce que fait cette IA, ni pourquoi elle t'a refusé. Quand tu reçois un mail de refus générique, il y a 9 chances sur 10 que ton CV soit passé par une chaîne d'agents automatisés avant d'atterrir chez un humain. Souvent même, aucun humain ne l'a lu.
Pour une vidéo, j'ai construit un outil de recrutement IA complet : scoring, anonymisation, refus explicable, préqualification. En une journée. Ce n'est pas un système prod-ready, mais la logique interne est la même que celle qui équipe la plupart des ATS (Applicant Tracking Systems) sur le marché.
Je vais ouvrir la boîte. Étape par étape. De l'offre publiée jusqu'au mail de refus. Parce que si tu es candidat, tu dois comprendre ce qui se passe de l'autre côté. Et si tu recrutes, tu dois savoir ce que tu achètes quand tu coches "oui à l'IA" dans la démo du commercial.
Étape 1 : l'offre génère sa propre grille de notation
Quand un recruteur publie une offre avec un outil IA moderne, il ne met pas que le texte en ligne. Il génère, ou l'outil génère pour lui, ce qu'on appelle une scorecard.
Une scorecard, c'est une liste de compétences (hard et soft) avec un poids chacune. L'outil lit l'offre, détecte les compétences mentionnées, et leur attribue une importance relative.
Sur un poste de consultant IA en fintech, la scorecard typique ressemble à :
- Maîtrise de Python / IA : poids élevé
- Conception d'outils d'automatisation : poids élevé
- Expérience fintech : poids moyen
- Travail en autonomie : poids moyen
- Anglais professionnel : poids faible
Le candidat, lui, ne voit jamais cette grille. Elle reste interne. C'est la première asymétrie : le recruteur évalue avec une règle précise, le candidat postule à l'aveugle.
Insight à retenir : la scorecard est quasi-reconstructible à partir de l'offre seule. Si tu colles l'offre dans Claude ou ChatGPT en demandant "donne-moi la grille de scoring probable pour cette offre", tu tombes à 80-90 % sur les mêmes critères que ceux générés en interne. Les modèles s'entraînent sur les mêmes patterns textuels, ils convergent.
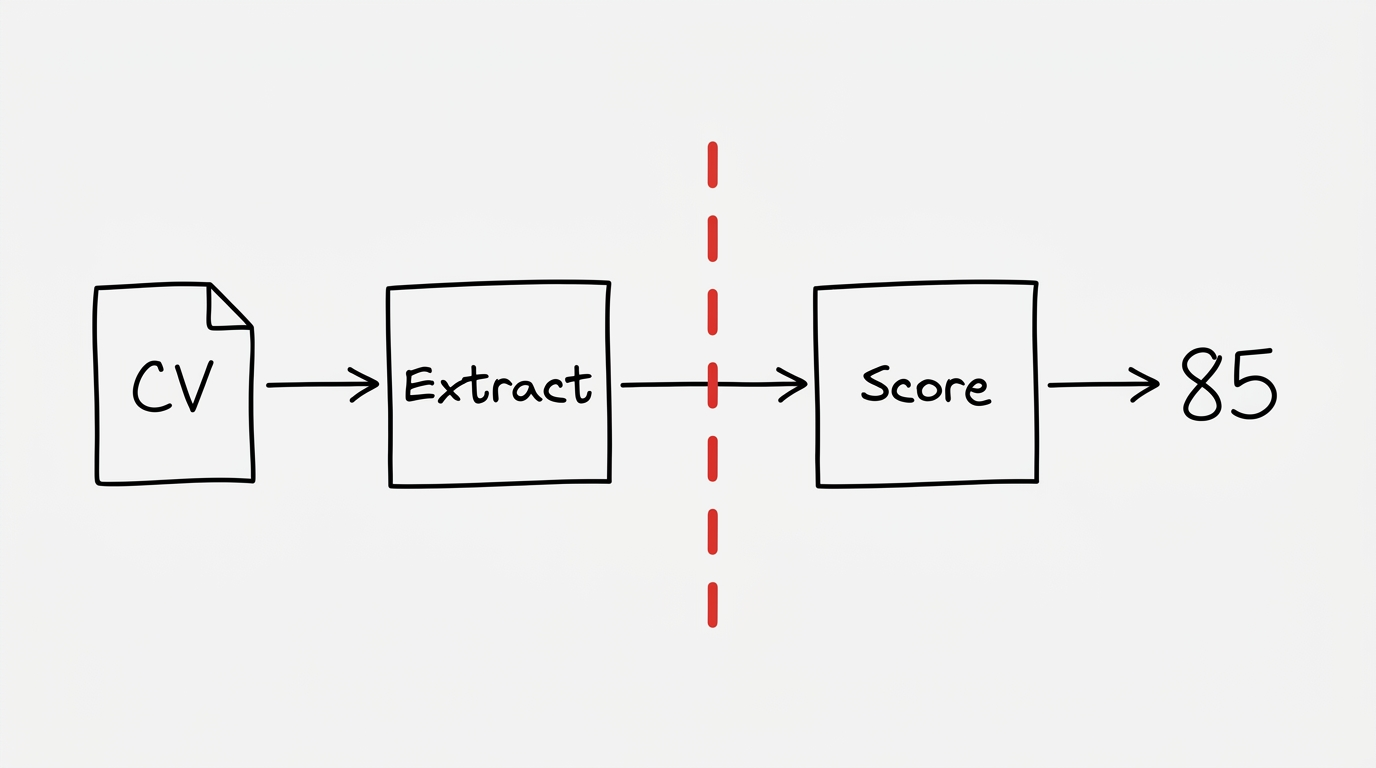
Étape 2 : l'extraction du CV
Quand tu déposes ton CV, il part dans un premier agent qui a un job précis : extraire du texte. Et uniquement du texte.
Ce premier agent fait trois choses :
- OCR si le CV est un scan ou une image
- Parsing du texte structuré (expériences, formations, compétences)
- Anonymisation : enlever nom, genre, âge, localisation précise, université si elle porte un signal
Ce dernier point est crucial. Sur un système bien construit, le deuxième agent (celui qui score) ne voit jamais ton nom, ton genre ou ton adresse. Il ne reçoit qu'un texte neutralisé.
Sauf que la majorité des ATS sur le marché ne le font pas. Ils passent le CV brut directement au scoring. Ce qui explique les biais documentés : des études récentes montrent que les LLM modernes favorisent les noms à consonance blanche dans 85 % des cas, et les noms à consonance noire dans 0 % des cas.
La séparation anonymisation / scoring en deux agents distincts est un choix d'architecture, pas une feature cosmétique. Un prompt unique qui fait les deux étapes en même temps laisse fuiter l'information. L'architecte du système doit le décider consciemment.
Si tu veux comprendre comment les IA traitent ton CV de manière automatique, regarde cette vidéo:
Étape 3 : le matching scorecard
Une fois le CV extrait et anonymisé, il part dans l'agent de scoring. Son job : prendre la scorecard de l'étape 1, prendre le CV anonymisé de l'étape 2, et attribuer une note par critère.
Pour chaque critère :
- L'IA cherche des signaux textuels dans le CV (mots-clés, expériences, durées)
- Elle attribue une note brute (ex : 0 à 10)
- Elle multiplie par le poids du critère
Puis elle somme. Note globale, typiquement sur 100.
Ce qui est contre-intuitif : l'IA ne lit pas entre les lignes. Elle matche. Si ton CV dit "chef de projet data" et que la scorecard cherche "data engineer", le match sera partiel même si les compétences sous-jacentes sont identiques. L'alignement lexical compte autant que l'alignement sémantique.
C'est pour ça que deux CV de la même personne, mêmes expériences, peuvent sortir à 62/100 et 82/100. La différence tient au vocabulaire, à l'ordre des sections, à la manière dont tu formules une expérience. Pas à ce que tu as réellement fait.
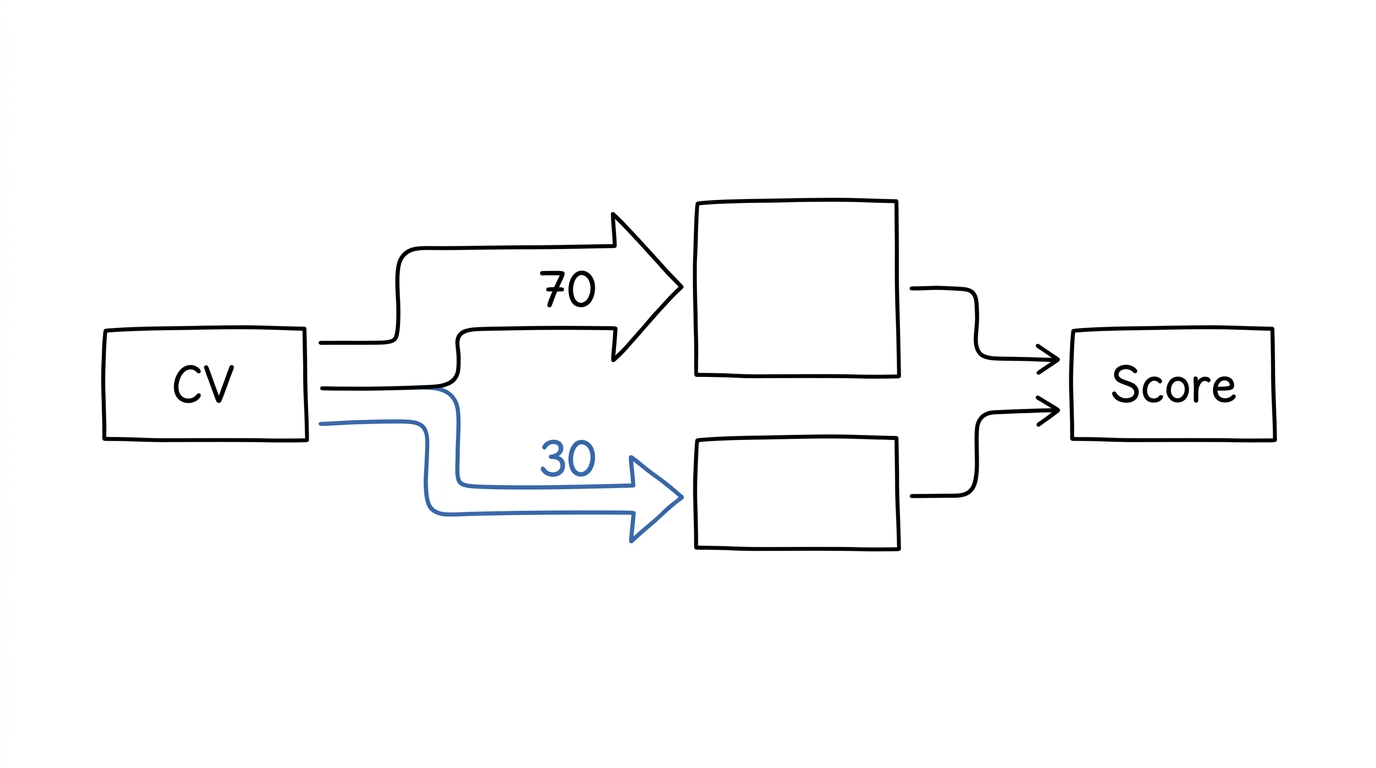
Étape 4 : le split 70/30
Un scoring pur scorecard, c'est un moule. Toujours les mêmes profils qui passent. Les reconversions, les parcours non-linéaires, les compétences transverses, tout ça passe à la trappe.
La parade qu'on peut coder proprement : 70 % scorecard stricte + 30 % évaluation généraliste.
- 70 % : le matching mathématique critère par critère. Objectif, reproductible, auditable.
- 30 % : une évaluation plus large, qui regarde les compétences transférables, la progression de carrière, les signaux qu'une scorecard ne capte pas.
Le ratio s'adapte au type de poste :
- Poste hyper-technique (DevOps senior, quant) : 80/20, la technique prime
- Poste transverse (product manager, directeur opérations) : 60/40, le transfert compte plus
- Poste junior : souvent 60/40, parce que l'expérience manque et il faut regarder le potentiel
C'est une ligne de code, pas une révolution méthodologique. Mais aucun ATS générique du marché ne te laisse configurer ce ratio. Tu prends le modèle qu'ils ont décidé, souvent 100 % scorecard, sans choix.
Étape 5 : la décision et le droit à l'explication
Le score sort. En dessous d'un seuil (souvent autour de 65-70/100), le candidat est refusé. Au-dessus, il passe à l'étape suivante : préqualification, entretien RH, etc.
Et c'est là que la loi entre en jeu.
Tout candidat peut demander à savoir pourquoi il a été refusé. C'est déjà vrai avec le RGPD pour les décisions automatisées. Ça devient incontournable avec l'AI Act européen, dont les obligations spécifiques au recrutement entrent en vigueur en 2026.
Concrètement, côté système, ça veut dire qu'à chaque refus, l'IA doit générer un motif argumenté. Pas un mail générique, mais un texte qui cite les critères de la scorecard et pointe précisément ce qui manquait dans le CV. Exemple : "Votre parcours est principalement orienté trading algorithmique et data science, alors que ce poste requiert une expérience en automatisation de processus métier."
C'est un ajout technique simple. Un prompt, une génération. Mais il doit être pensé en amont, pas collé à la fin. Beaucoup d'ATS l'ajoutent maintenant en urgence avant l'échéance AI Act. Ceux qui ne le feront pas à temps vont être en infraction par défaut. 98 % du marché sans explicabilité by design, c'est le point de départ.
Étape 6 : la supervision humaine (et pourquoi elle ne marche pas toute seule)
L'argument préféré des boîtes qui déploient ces systèmes : "c'est toujours un humain qui décide en dernier."
Une étude de l'Université de Washington publiée en novembre 2025 montre que les humains suivent la recommandation de l'IA dans 90 % des cas. Même quand elle est biaisée. Même quand les biais sont documentés.
Ce n'est pas une question de mauvaise volonté. C'est structurel :
- Biais d'ancrage : la note est affichée avant la lecture, le cerveau s'accroche à ce chiffre
- Surcharge : un recruteur qui traite 250 candidats pour un poste n'a pas le temps d'auditer chaque reco
- Design UX : la plupart des ATS rendent le rejet plus rapide que l'approfondissement
La supervision humaine "effective" au sens de l'AI Act n'existe que si l'outil force le temps de lecture, cache le score avant l'argument, et permet de challenger la reco facilement. Sinon, c'est du théâtre juridique.
Ce qui devrait changer
Aujourd'hui, le marché du recrutement IA est un mélange de deux choses. D'un côté, des ATS historiques qui ont collé de l'IA par-dessus une architecture pensée pour du filtrage par mot-clé. De l'autre, des startups qui vendent de la "IA explicable" sans toujours implémenter les garde-fous derrière.
Un système aligné avec les standards 2026 et la réglementation qui arrive a minima :
- Anonymisation en 2 agents séparés, extraction d'un côté, scoring de l'autre, aucun passage d'info identitaire entre les deux.
- Scorecard transparente, documentée, versionnée, auditable a posteriori.
- Split 70/30 configurable, pour ne pas exclure les profils atypiques by design.
- Motif de refus généré automatiquement, pas en option, par défaut.
- UX de supervision : score caché avant lecture, temps de lecture minimum, bouton "challenger cette reco" présent.
- Logs auditables, pour la conformité AI Act et pour les litiges candidats.
Aucun de ces points n'est techniquement difficile. La différence entre les systèmes justes et les autres, ce n'est pas la technique. C'est la décision de les concevoir ainsi dès le départ.
Un ATS qu'on achète clé en main, on ne décide pas. On prend ce que le vendeur a décidé. Avec l'IA générative, le coût du code tend vers zéro : une journée pour un système fonctionnel, quelques semaines pour un système prod-ready. La question n'est plus "acheter une solution ?" mais "pourquoi on achèterait ?" quand on peut architecturer exactement ce dont on a besoin.
Si tu recrutes aujourd'hui avec un outil IA, trois questions à poser à ton fournisseur :
- Est-ce que l'extraction et le scoring sont dans deux agents séparés, avec anonymisation entre les deux ?
- Comment est calculée la note : 100 % scorecard, ou il y a un composant plus généraliste ?
- Comment est généré le motif de refus quand un candidat en fait la demande ?
Si les réponses sont floues ou si la démo "fait tout en un seul prompt", change de fournisseur. Ou construis le tien.