IA vocale en direct : le vrai déclic, c'est la latence
Une IA vocale en direct peut analyser un appel et ressortir la bonne connaissance en moins de 2 secondes. Voici ce que ça change.
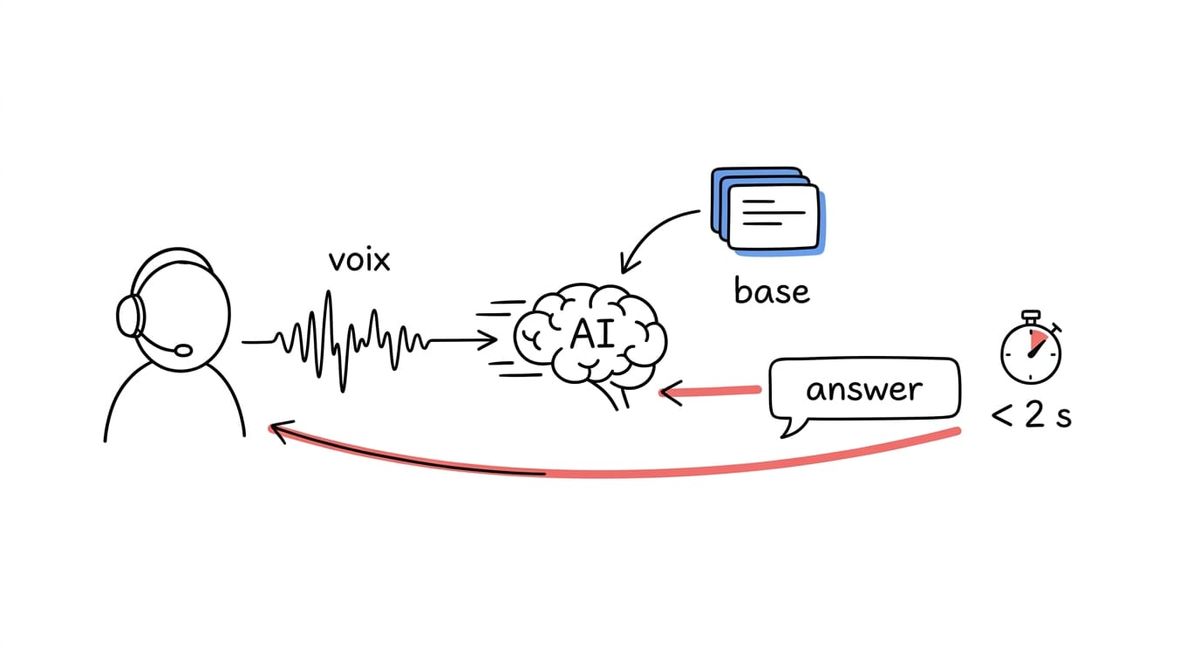
Une IA vocale en direct devient utile à partir du moment où elle peut écouter, comprendre, chercher dans une base de connaissance et proposer une réponse avant que l'humain ait déjà changé de sujet. Pour moi, le vrai seuil n'est pas "est-ce que l'IA sait répondre ?". C'est : est-ce qu'elle sait répondre en moins de 2 secondes ?
J'ai construit un prototype pour tester cette limite.
Pour comprendre ce qui devient possible quand on combine transcription temps réel, modèles rapides et base de connaissance métier.
Le résultat intéressant, c'est ce que l'expérience révèle : on arrive dans une phase où l'IA ne sert plus seulement à produire du contenu après coup. Elle peut commencer à accompagner une décision pendant qu'elle est en train de se produire.
Pourquoi l'IA vocale en direct change le rapport à la connaissance
La plupart des outils IA actuels fonctionnent en différé.
Tu termines une réunion, puis l'IA fait un résumé.
Tu termines un appel commercial, puis l'IA t'explique ce que tu aurais dû répondre.
Tu finis une session support, puis l'IA classe les objections.
C'est utile. Mais ça reste de l'analyse après bataille.
Le vrai changement arrive quand l'IA intervient pendant l'action. Pas pour remplacer l'humain, mais pour lui remettre sous les yeux la bonne information au bon moment.
Dans mon prototype, le scénario était simple : un appel commercial en cours. Le client formule une objection, par exemple sur le prix, la concurrence ou le fait qu'il doit "réfléchir". L'IA écoute, détecte qu'un moment important vient d'arriver, cherche dans une base de connaissance commerciale et propose une réponse courte.
Pas un script complet.
Pas une tirade à réciter.
Juste une stratégie, une phrase possible, ou une question à poser.
Ce détail compte. Dans un contexte réel, tu n'as pas besoin d'un rapport de 3 pages. Tu as besoin d'un appui utilisable maintenant.
Une IA qui répond parfaitement avec 10 secondes de retard ne sert presque à rien en direct. Une IA imparfaite mais pertinente en 1,5 seconde peut devenir un copilote.
Le vrai verrou de l'IA temps réel n'est plus seulement la qualité
Pendant longtemps, on a parlé de l'IA comme si le problème principal était la qualité des réponses.
Est-ce que le modèle comprend ?
Est-ce qu'il raisonne ?
Est-ce qu'il hallucine ?
Ces questions restent importantes. Mais pour les interfaces vocales en direct, le goulot d'étranglement se déplace : la latence devient un critère produit central.
La latence, c'est le temps entre ce qui se passe dans la vraie vie et le moment où l'IA peut réellement aider.
Sur une interface classique, 5 secondes peuvent sembler acceptables. Tu poses une question à ChatGPT, tu attends, tu lis. Ce n'est pas très grave.
Dans une conversation humaine, 5 secondes sont une éternité.
Si le prospect dit "c'est trop cher" et que l'IA te souffle une réponse 7 secondes plus tard, tu as déjà commencé à parler. Tu es peut-être parti sur une justification faible. Tu as peut-être répondu au prix au lieu de recadrer sur la valeur. Le bon conseil arrive trop tard.
C'est pour ça que le seuil des 2 secondes est si important. En dessous, l'information peut encore influencer l'action. Au-dessus, elle devient souvent une analyse post-mortem.
Les briques techniques commencent à rendre ce seuil atteignable. Deepgram (un service de transcription vocale en temps réel, utilisé pour transformer un flux audio en texte exploitable par une application) explique par exemple que la latence d'une transcription streaming se découpe en plusieurs composants, et donne des ordres de grandeur typiques de 200 à 500 ms de latence totale de transcription, selon les conditions. Anthropic présente aussi ses petits modèles comme Haiku 4.5 comme adaptés aux usages à faible latence, notamment les assistants et agents en temps réel (source officielle Anthropic).
Mais la conclusion n'est pas "il suffit de prendre les bons outils".
La conclusion, c'est qu'il faut architecturer le workflow autour de la vitesse.
Le workflow général d'une IA vocale en direct

Le système que j'ai construit peut se résumer en 5 étapes.
Première étape : écouter.
Il faut capter le micro, mais aussi le son de l'interlocuteur. Dans un appel réel, ce n'est pas seulement "ma voix". C'est la conversation complète qui compte.
Deuxième étape : transcrire.
L'audio doit devenir du texte presque immédiatement. C'est la base de tout le reste. Si cette brique est lente, tout le système est lent.
Troisième étape : détecter le moment utile.
On ne veut pas que l'IA parle tout le temps. Une bonne IA en direct doit surtout savoir se taire. Elle doit repérer les moments où une aide a de la valeur : objection, confusion, demande de clarification, comparaison avec un concurrent, signal d'achat, inquiétude.
Quatrième étape : chercher dans la base de connaissance.
C'est là que le RAG intervient. Le RAG (retrieval-augmented generation) consiste à connecter un modèle à une base de connaissance externe pour produire des réponses plus pertinentes et plus ancrées dans des documents réels. IBM le décrit comme une architecture qui relie un modèle à des bases de connaissance externes pour améliorer la pertinence des réponses (définition IBM).
Dans mon cas, la base contenait 577 fiches structurées extraites de contenus commerciaux. Chaque fiche résumait une situation : objection prix, comparaison concurrent, hésitation, statut quo, qualification, découverte, closing.
Cinquième étape : générer une aide courte.
La sortie doit être compacte. Une stratégie. Une phrase. Une question. Un angle. Pas une dissertation.
La structure ressemble donc à ça :
- Audio en direct
- Transcription streaming
- Détection d'un moment important
- Recherche dans la base de connaissance
- Suggestion courte pour l'humain
Sur le papier, ce workflow paraît simple.
En pratique, chaque étape doit être pensée pour ne pas voler 500 ms de trop.
La base de connaissance compte plus que le modèle

Le point le plus sous-estimé dans ce type de système, c'est la base de connaissance.
Beaucoup de personnes regardent d'abord le modèle : quel LLM ? Quelle taille ? Quel benchmark ? Quel prix par token ?
Mais dans une IA métier en direct, la valeur vient surtout de ce qu'elle sait chercher.
Un modèle généraliste peut improviser une réponse à une objection commerciale. Il dira probablement quelque chose de correct. Mais "correct" ne suffit pas toujours.
La vraie valeur, c'est quand le système retrouve une logique commerciale précise, issue de bons exemples, et l'adapte à la conversation en cours.
C'est pour ça que j'ai construit une base de 577 fiches plutôt que de demander simplement au modèle : "réponds bien à cette objection".
Une base de connaissance bien structurée change la nature du système.
Elle transforme l'IA d'un générateur de texte en moteur de rappel métier.
Chroma (une base de données vectorielle open source, pensée pour stocker des embeddings et retrouver les documents les plus proches d'une requête) explique que les embeddings sont des représentations numériques qui capturent le sens des données, ce qui permet de rechercher efficacement du contenu similaire (documentation Chroma). Dit plus simplement : au lieu de chercher un mot exact dans un titre, le système cherche une idée dans le contenu.
Si un prospect dit "on travaille déjà avec quelqu'un", la base peut retrouver une fiche sur le statut quo ou la comparaison concurrentielle, même si les mots exacts ne sont pas les mêmes.
C'est là que le système devient intéressant.
Pas parce qu'il "parle".
Parce qu'il retrouve la bonne connaissance au bon moment.
Ce que ça implique pour les entreprises
Les entreprises ont souvent accumulé des bases de connaissance énormes.
Des procédures.
Des formations.
Des tickets support.
Des scripts d'appel.
Des comptes rendus de réunion.
Des retours terrain.
Des documents internes que presque personne ne consulte parce qu'ils sont trop longs, mal indexés, ou simplement enfouis dans un outil.
Le problème n'est pas toujours l'absence de connaissance. C'est l'accès à cette connaissance au moment exact où elle sert.
Une IA vocale en direct rend ce problème très concret.
Elle force à se poser trois questions :
- Quelle information doit remonter pendant l'action ?
- À quel moment exact doit-elle remonter ?
- Sous quelle forme l'humain peut-il l'utiliser sans être distrait ?
C'est une logique très différente du "chatbot interne".
Un chatbot attend qu'on lui pose une question.
Un copilote temps réel observe un process et intervient quand il détecte un moment utile.
Ce n'est pas la même promesse. Ce n'est pas la même architecture. Ce n'est pas non plus le même niveau d'exigence sur la latence, la pertinence et l'expérience utilisateur.
C'est pour ça que la méthode compte plus que l'outil. Chez Kalybra, on parle souvent de process IA : architecturer le workflow, le mettre en production, puis le calibrer avec les retours réels. Sur ce type de cas, cette boucle devient indispensable.
Tu ne peux pas savoir à l'avance quelles suggestions seront vraiment utiles.
Tu dois les mesurer.
Tu dois voir lesquelles arrivent trop tard.
Tu dois repérer celles que l'utilisateur ignore.
Tu dois réduire ce qui distrait et renforcer ce qui aide.
Le produit ne s'améliore pas seulement en changeant de modèle. Il s'améliore en calibrant le process.
Ce que j'ai retenu de l'expérience
Mon prototype n'était pas un produit fini.
Il tournait plutôt autour de 2 à 3 secondes dans mes tests. C'est déjà proche d'un usage réel, mais pas encore assez stable pour être confortable tout le temps. L'objectif est clair : descendre régulièrement sous les 2 secondes.
Mais même avec cette limite, l'expérience m'a appris quelque chose.
On peut déjà construire des systèmes qui :
- écoutent une conversation en direct,
- détectent une situation métier,
- interrogent une base de connaissance spécialisée,
- synthétisent une aide utilisable,
- affichent le tout pendant que l'humain peut encore agir.
Ce n'est plus de la science-fiction.
Ce n'est pas non plus magique.
C'est un assemblage de briques techniques, avec une contrainte produit très forte : la connaissance doit arriver avant que la fenêtre d'action se referme.
C'est là que beaucoup d'entreprises vont découvrir un nouveau terrain.
Pas seulement "automatiser des tâches".
Mais augmenter des moments de décision.
Le commercial qui reçoit la bonne objection.
Le support qui retrouve la bonne procédure.
Le manager qui voit remonter un signal faible pendant un point d'équipe.
Le formateur qui sait immédiatement où l'apprenant bloque.
Le sujet n'est pas que l'IA parle avec nous. Le sujet est qu'elle peut faire remonter notre propre connaissance collective au moment où on en a besoin.
Et quand ce moment dure 2 secondes, toute l'architecture doit être pensée autour de lui.
Questions fréquentes
Qu'est-ce qu'une IA vocale en direct ?
Une IA vocale en direct est un système qui écoute une conversation, la transcrit en temps réel, analyse ce qui se passe et propose une aide pendant que l'échange est encore en cours.
Pourquoi le seuil des 2 secondes est-il important ?
Parce qu'une suggestion doit arriver avant que l'humain ait déjà répondu ou que la conversation ait changé de direction. En dessous de 2 secondes, l'IA peut encore influencer l'action. Au-dessus, elle ressemble souvent à une analyse après coup.
Le RAG est-il indispensable pour une IA vocale métier ?
Pour un usage métier sérieux, oui dans la plupart des cas. Le RAG permet à l'IA d'aller chercher des informations dans une base de connaissance spécifique au lieu de répondre uniquement avec sa connaissance générale.
Est-ce que ce type de système remplace l'humain ?
Non. Le meilleur usage consiste à augmenter l'humain pendant l'action. L'IA propose une information ou une stratégie, mais c'est l'utilisateur qui choisit quoi dire, quand le dire, et comment l'adapter au contexte.